|
|
Germanic Lexicon Project
How to digitize a text |
|
Part 1: Data entry
Typing
Although most texts are digitized using scanning and OCR, you can hand-type a text if you prefer. This is generally slower, but you might prefer a low-tech approach or might not have access to scanning and OCR.
The glossary to Bright's An Anglo-Saxon Reader was entered by typing. Back in 1999, I organized volunteers thru the ANSAX-L mailing list. I xeroxed the glossary and mailed 6 xeroxed pages to each volunteer thru the U.S. Postal Service. I asked the volunteers to email the typed text back to me. I joined the pages into one document and regularized the character encoding.
At this writing (2004), I would only consider typing in a case where OCR is impractical, as in the case of handwritten notes. It's true that OCR usually gives degraded results on old yellowed books typeset in archaic typefaces, especially when there are lots of special non-English characters; but I still find it to be much less effort to correct the errors than to type the whole thing. But, if you prefer to type, go ahead.
Scanning
An ordinary inexpensive flatbed scanner works just fine when scanning for OCR, but it is slow (you might be able to scan 1 or 2 pages per minute). I use a networked office copier which can scan as quickly as it can make copies (if I put sheets in the document feeder, it can scan around 35 pages a minute; but of course it's slower if I have to turn the pages of a book).
I usually scan both the right and left pages together as one image, except in rare cases where it's such an unusually large book which won't fit on the glass. I use Photoshop to split the picture into two after I scan, as described below.
I recommend at least 300 dpi (dots per inch) as the scanning resolution; the higher the resolution, the better the results from an OCR program. It is really worth it to spend some time experimenting with the different scanning settings; I've found that despeckling in particular gives greatly improved OCR results. TIFF is the most commonly used file format for scanning and OCR.
Renaming files
After you have done the scanning, I strongly recommend renaming your image files so that the filenames match the page numbers. This takes some time, but it will save you many headaches later, and is also a good way to find out which pages you have missed before you return the library book which took two weeks to get thru Interlibrary Loan.
Another page in this About section describes a scheme for naming files so that the pages stay in the right order, which is very helpful.
Post-processing the images
Altho it is not strictly necessary, I recommend doing some post-processing on your images. One thing you can do is to divide the left and right pages into separate files. I usually make two little batch-mode macros in Photoshop to do this, one macro for the left page and one for the right. I leave an ample margin when setting the crop area, since each page is always positioned a little differently when you scan.
When I split the left and right pages into separate files using Photoshop, I put the right-side (odd-numbered) pages in a separate directory. Then I run a little script I wrote which renames each file by adding one to the number in the filename, so that b0004.tiff becomes b0005.tiff.
Then you can hand-process each image to un-tilt the text and to crop away the dark margins, which takes me a few hours for an average book (I am sure that a fully automated image processing solution must be possible; if you know of one, please let me know). Getting rid of the margins makes the files smaller, which is a consideration if you're going to be publicly posting the page images. The way I do this myself is to use the drag tool to drag the whole image so that the upper left corner of the text is lined up with the upper left corner of the image border. Then I run a batch macro to crop away the right and bottom portions of each image.
Un-tilting the text isn't quite as important since most OCR programs do this automatically, but there have been cases where I have found it useful For example, I wrote a series of scripts which printed the image each entry in the Torp dictionary right above the online version of the text, so that I could compare the two and mark corrections with a pen while riding the train. The necessary image processing was much easier to do with un-tilted images.
OCR
Getting good results from an OCR program is as much art as science. It is really worth it to experiment with the settings and spend some time seeing what improves the results, because even a small gain will save a lot of time on the corrections. Some OCR programs will let you train the program on a sample page, so that it can learn the typefaces being used. Some will let you say what characters you want to allow, a big consideration since many texts on pre-modern languages contain unusual characters.
No OCR program lets me save the files in the exact format I want. What I usually do is output each page as a separate HTML file. Then I write a script to which strips off the HTML preamble and coda, which I don't need. This leaves only the text itself, containing the HTML entities and markup tags for boldface and italics. Then I join all the files together into one big file, using a little script to add a page break marker at the top of each page:
<PAGE NUM="b0005"/>
(Page marker for the beginning of page 5 of the main text; I get the page number from the filename which I already made match the page number as described above.)
I recommend that you don't throw away your image files when you're done with scanning. It's good to post them on the web so that other people can immediately look to see whether an apparent error is in the original or not (you'll always miss some errors when you correct). Also, you may need to repeat the OCR at some point. In the case of my own projects, I've sometimes worked out elaborate systems for printing the original scanned image on the same page as the online text for easy comparison.
Part 2: Correction
Even after I carefully train the OCR on sample pages, the output text is often so degraded that some people would probably rather give up and enter the data by hand instead. However, there is usually some regularity to the errors; the same errors tend to happen over and over. We can take advantage of this partial regularity to greatly reduce the number of hand-corrections which must be made.
Global corrections
Before I start hand corrections, I do some global cleanup of the file.
A typical sort of error is that þ (Germanic thorn) often comes out as P, p, or b, but you can't simply change P to þ since P is sometimes correct (sometimes the text really does contain a capital P). What you might do is to change P to þ except when the P is at the beginning of a word. This will usually give a correct substitution. It won't work for b or p, since these letters can occur in the middle of a word; but it's still worth doing for P.
Here are a few of the many global substitutions I did on Bosworth/Toller:
- Remove the <SUB> and <SUP> tags, since these are never correct (there were a few dozen instances of each)
- If a comma comes immediately before a letter without a space in between, insert a space.
- Replace <I>-</I> (an italicised hyphen) with - (a plain hyphen, since a hyphen alone should never be italic).
- Replace ].</I> with </I>]. (A square bracket should not be italicized even if the immediately preceding text is italic.)
- etc.
There is no easy way to determine which global changes will be beneficial. You simply have to study your file and notice what is repeatedly going wrong, and figure out what changes you can make without introducing a lot of new errors. This is something that you get better at as you do it more.
In practice, I usually do some global corrections, then hand correct a few pages. Then I go back and do another round of global corrections because I notice more possible strategies while doing the hand corrections.
Writing scripts
If you know how to program, you can often come up with various schemes to automatically detect and correct errors.
For example, in German texts, the characters ä, ö, ü are all often misrecognized as a 6. A program can readily detect that a word such as sch6n must contain an error, because 6 cannot occur in the middle of a word which begins with letters. But which of the possible corrections is the right one: schän, schön, or schün? A human who speaks German readily knows that it must be schön, but how can a computer tell this?
What your program can do is to try every substitution and see whether there is more than one possibility in a German dictionary. If only schön actually exists, we can reasonably assume that this is the correction, and automatically make the substitution.
I produced the list of possible substitutions with a recursive algorithm which reads the characters left-to-right; at each recursion, the routine examines the present character and calls itself recursively for each possible substition, so that we branch thru all of the possibilities and assemble a list (this strategy works, but it is rather slow; if you know of a faster algorithm, please let me know).
This technique will occasionally introduce new errors, but on the whole, it is enormously faster than making the same corrections by hand. Over 6000 corrections were made to the Torp dictionary at a single pass.
Hand corrections
Global and automated corrections can get you a fair distance toward a corrected text. In the end, however, there is no avoiding checking and correcting the text by hand. This is by far the most time-consuming portion of the entire project, but it is unavoidable.
One way to correct your text is to set the original book beside your computer, and compare the book with your online text by looking back and forth between the book and your screen. You can do this, but I find it extremely tedious and hard on the eyes.
What I prefer to do is to print out the online text and original page image, set them side by side, and mark my corrections with a red pen. This takes advantage of the fact that humans catch a substantially higher percentage of errors on paper than on the screen. It also has the advantage that you don't need to be near a computer to mark the errors (for example, during a long road trip from Philadelphia to Denver, I marked up the errors in the online version of the readings in Gordon/Taylor's textbook of Old Icelandic.
I usually need to represent some characters with entities such as &e-long-acute; or &hw;. This is obviously hard to read, so it's better if I can print out the text in a more human-readable form to compare against the original page image. My way of doing this is to write a Perl script which typesets my working file by producing a TEX file (TEX is a typesetting system of unparalleled quality and flexibility; it has been around for decades and is available for free).
If you're not a programmer, you can often produce a more readable form of your document by doing a bunch of appropriate search-and-replace operations on a copy of your file before printing it.
A convenience I worked out for the Fick/Falk/Torp corrections was to work out a macro in the Emacs text editor. While editing the dictionary file, I could hit a key to pop up a window displaying the scanned image of the dictionary entry corresponding to the current location of the cursor in the Emacs window. This was very handy.
Part 3: Markup and validation
I mark up my base document in XML (a markup scheme). Then I derive other kinds of documents from the XML base document:
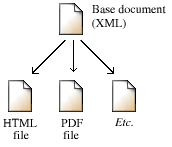
Whenever additional corrections need to be made, you make them in the base document, and then automatically regenerate the derived formats.
This method has so many advantages to it that it has come to be generally accepted as best practice among professionals who manage and archive text and present it in multiple presentation formats.
What XML is, and why it is a really good idea
In HTML, you can mark up text for attributes such as boldface or italics, as in this entry from Bosworth/Toller:
a-berstan; p. -bearst, pl. -burston; pp. -borsten; [a, berstan] To burst, break, to be broken; perfringi. v. for-berstan.
Here is how this entry might be marked up with HTML tags:
<p>
<b>a-berstan;</b> <i>p.</i> -bearst, <i>pl.</i> -burston; <i>pp.</i> -borsten; [a, berstan] <i>To burst, break, to be broken;</i> perfringi. v. for-berstan.
</p>
Notice that italics are used to represent two different kinds of text: part of speech tags such as pl. and pp., and the modern English gloss (To burst, break, to be broken). If you're only concerned with making a web page look like the original paper page, then the tags <i> and <b> are enough. However, there are very good reasons for not using the same tag to denote these two different kinds of information. For example:
- If you are building a search system, you might want to allow the user to limit the search to just the glosses or just the part-of-speech fields. If you used separate tags for the two, your search system can tell which is which.
- You might change your mind later and decide to visually represent only one of the two fields with italics. If you have used the <i> tag for both, there is no straightforward way to tell which is which.
- If you mark up the part-of-speech tags separately, you can validate them (i.e., check them for errors) by comparing those fields against a list of known tags.
- If you mark up the modern English glosses separately, you can validate them by extracting them and running them thru a standard spell checker.
For these reasons and others, it is better if you use semantic tags (tags which tell what kind the information is) rather than presentation tags (tags which describe how to visually render the text).
XML is a markup system similar to HTML. A major difference is that in XML, you get to make up your own tags for whatever purpose you need. Following is a possible representation of the entry above in XML:
<entry>
<headword>a-berstan;</headword>
<pos>p.</pos> <inflected-form>-bearst,</inflected-form>
<pos>pl.</pos> <inflected-form>-burston;</inflected-form>
<pos>pp.</pos> <inflected-form>-borsten;</inflected-form>
<etym>[a, berstan]<etym>
<gloss lang="en">To burst, break, to be broken;</gloss>
<gloss lang="latin">perfringi.</gloss>
<xref>v. for-berstan.</xref>
</entry>
Notice that the headword is marked up with <headword>, the part-of-speech tags with<pos>, the etymology with <etym>, and so on.
This isn't necessarily the best way to represent this particular entry in XML, but the important point is that the data is marked up to show what kind it is, not how to display it. The display details are properly the concern of the programs which convert the abstract XML document into concrete presentation forms such as PDF, PostScript, HTML, or RTF.
So if you want to mark up a plain-text document, I think that the best thing would be for you to use semantic tags. You can study some of the other examples on this site to see what to do. I also recommend reading up on the TEI guidelines, which define a standardized set of tags to use in projects of this kind.
However, if you don't completely understand what I mean by semantic tags or if you find it awkward to use them, it's certainly better than nothing if you mark up fields with attributes such as italic, bold, etc. If you've been consistent, a good programmer can often partially or fully recover the semantics of the fields based on context.
Scripts for markup
If you wanted, you could do all of your XML markup by hand, but this would be extremely tedious. I usually write a Perl script to do most of the markup automatically, and then make corrections to the markup by hand. I'm not going for elegance in parser design here; I just exploit whatever convenient properties the glossary has to get the job done.
For example, here's a typical line from Wright's Gothic glossary:
alls, aj. all, every, much, 227, 390, 427, 430 OE. eall, OHG. al.
My parser for this glossary basically peels off one layer at a time. First, it scans each word going left-to-right, looking for keywords like OE or OHG which start the etymological section; upon finding such a keyword, the script splits off that word and everything to the right. Next, it works right-to-left, removing the number list one item at a time, until it hits a word which is not a number. Then it takes the headword off of the beginning, and then removes the part-of-speech abbreviations. Whatever is left is taken to be the definition. Then the script just spews all of these lists to the output, adding the appropriate tags. (The whole process is slightly more complicated than this, but this is the basic idea.)
This is hardly an example of elegant programming, but it's quick to code, and it gets nearly all of the entries right. I correct the few remaining problematic lines by hand.
Validation
Even with all of your hand checking, there will always still be some errors, both in the markup and in the data themselves. You can make many kinds of errors reveal themselves by means of validation tests.
The type of validation depends on the type of data. Here are some tests I typically use:
- I make histogram of all of the characters in the file (e.g. the letter "a" occurred 7866 times, the letter "b" occurred 2410 times, etc.). This is a good way to find certain kinds of mistakes. For example, it is very unlikely that the yen ¥ symbol belongs in an text about Old Icelandic written in 1874.
- I make sure that my XML file is in valid format by using rxp, a Unix command line program. Among other things, this ensures that all of my entities (such as þ) and tags (such as <pos> or <etym>) are ones which I've declared to be legal. It makes sure that all of the tags balance (every <pos> is followed by a </pos>). It makes sure that every entity is closed with a semicolon, etc.
- I write a little program to extract the headwords and confirm that they are in alphabetical order; if they aren't, there's either a data entry error or an error in the original text.
- I make a histogram of the part-of-speech abbreviations in the part-of-speech fields. Sporadic errors tend to be at the bottom of the list and are usually readily apparent.
- I spell check the glosses in modern English or German against a dictionary of words in the respective language. (You can extract the gloss fields from your file, open the file containing the extracted fields in any word processor, and use the spell checker.)
- If I have a corpus of the pre-modern language (such as the Project Ulfila corpus of Gothic or the Toronto corpus of Old English), I check words in those languages against the corpus as a kind of spell checking. (I just use sort -u to produce a word list, make a big hash in Perl, and check words against it). There are various complications; for example, an Old English glossary might standardize the headwords to West Saxon orthography, even in cases where the word in question is not attested in West Saxon and doesn't appear in the corpus in the listed form. So some hand work is still necessary, but this kind of automated check is better than nothing.
- I'll take advantage of whatever useful properties a glossary has. For example, notice in the Wright example above that the paragraph references are in ascending numeric order (e.g. 7, 15, 109, 113, 207). It's easy to automatically confirm that the numbers are ascending; it must be an error if the value ever descends (and I did shake out some errors this way).
- I look for characters in unexpected positions. For example, the word fa1l has a number 1 in place of one of the lower-case L's. This is easy to miss in the hand-checking because the two symbols are so much alike. I might do this by searching for words where a letter is immediately followed by a number, which is usually wrong.
Other file formats.
There are two important considerations to keep in mind when considering what file formats to use:
1. Your digitized data will still be useful 10 years from now. However, it's very unlikely that very many people will still be using today's word processor formats 10 years from now. It might be difficult to find software which can even open the files.
2. It's often useful for data to be presented in more than one format. For example, one might want both an HTML and a PDF version of the same document. Conversions between presentation formats can be problematic; for example, it would be very difficult to convert a PDF file to an HTML file. Also, exporting from proprietary word processors is often not as straightforward as it seems.
It is because of these considerations that many professionals who have to manage data have adopted a model in which an abstract base document (often encoded in XML) can be automatically converted to any desired presentation format. XML has a simple and transparent structure which a programmer can easily work with; therefore data in XML will remain usable indefinitely.
Here are some comments on certain file formats:
PDF and PostScript: these file formats allow you near complete control over the way the data appear when the user views them. However, the data are in a frozen form, meaning that it is basically impossible to extract the data from the file and use it for some other purpose. The user might want to reprocess and reuse the data in all kinds of useful ways which you might not have envisioned. So it's OK to use the formats as a supplementary presentation format, but I strongly recommend against making them the only way you publish your data.
Microsoft Word and other proprietary word processors: Word has the advantage of being widely used by Windows and Macintosh users, at least at present. However, there are some significant disadvantages:
- The files are in a binary-barf format, which makes it very difficult for a programmer to manipulate the data. You can export the data to another format, but word processors rarely export the data cleanly; there are usually anomalies in the output format which the programmer has to fix by hand. (If you are using Word for your base document, this means that this cleanup will need to happen every time you make further corrections and re-export the data, which is obviously not a good solution.)
- Special characters, and text attributes such as bold and italic, might look good when you open the file with the word processor you created it in. However, since each word processor has its own quirky ways of storing this kind of information, these characters and attributes tend to get mangled or lost when you try to do anything else with the data.
- Most importantly, word processor formats tend to go obsolete fairly quickly (for example, I have hundreds of MacWrite II files from the early 1990s which I now have no staightforward way of opening). Microsoft changes the Word file format every few years. Think ten years down the road: your data will probably still be of valuable, but they will be useless if they are locked up in a word processor format which nobody uses any more.
Of course, a big consideration is the tools you have available to you and are familiar with. The biggest thing is digitizing and correcting the text, so go ahead an digitize even if you don't act on all of the recommendations made here.